Problem Statement & Technical Challenges
Traditional sentiment analysis systems force impossible tradeoffs between cost, accuracy, and latency
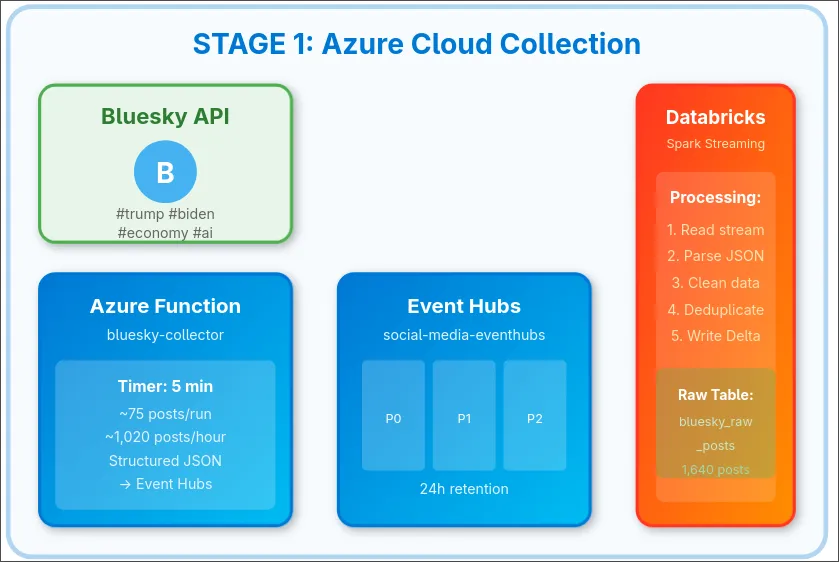
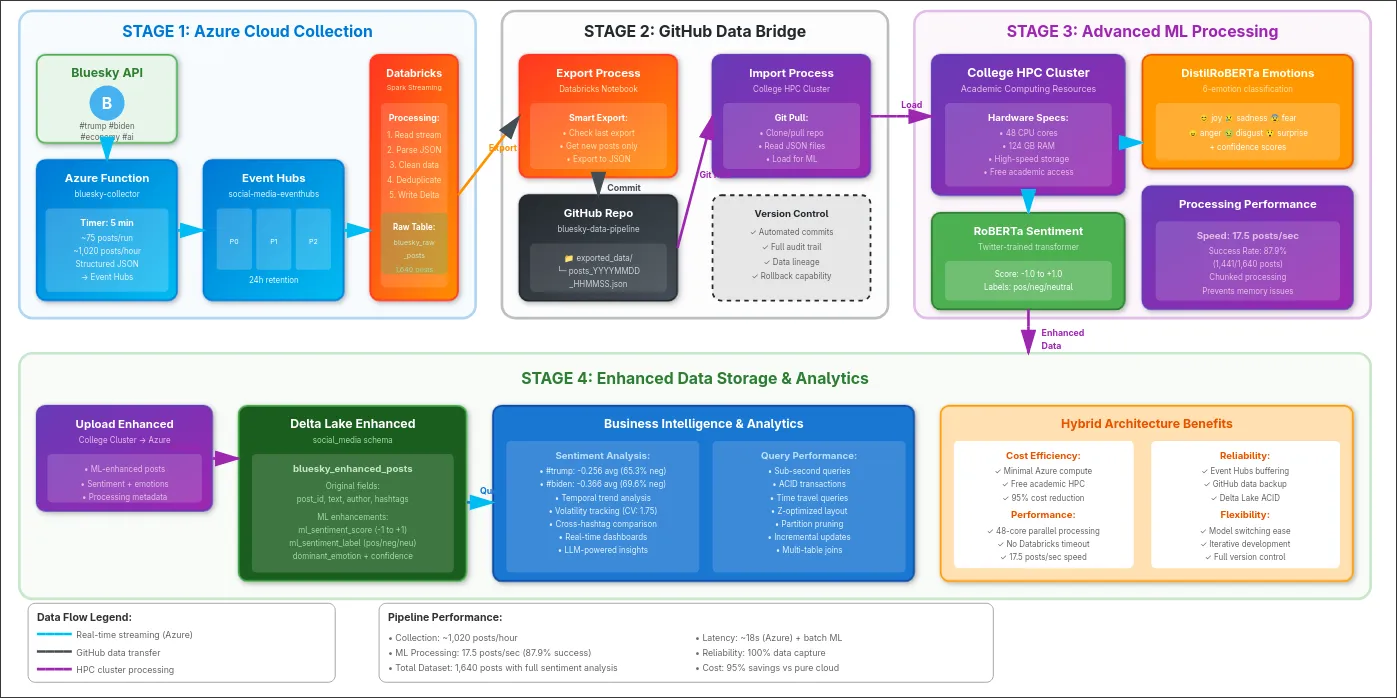
Real-Time Processing Constraints
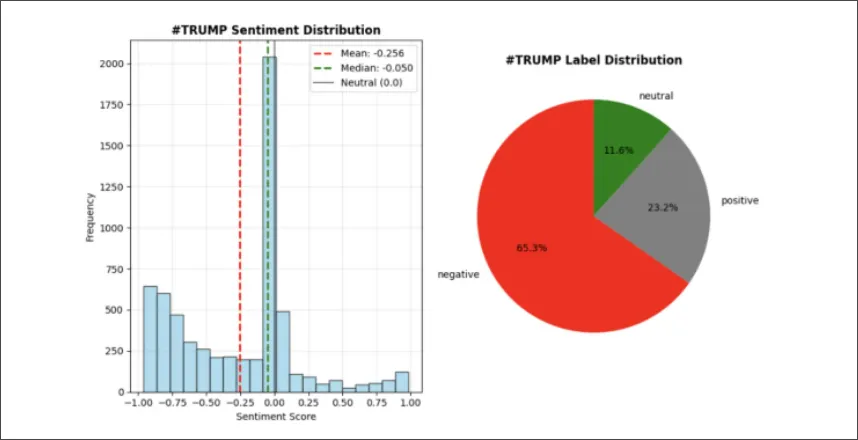
Traditional batch-based sentiment analysis operates on scheduled intervals (hours or days), creating temporal gaps between data collection and actionable insights. This prevents organizations from tracking continuous sentiment evolution, detecting rapid opinion shifts, or generating temporal sentiment graphs essential for crisis management and campaign monitoring.
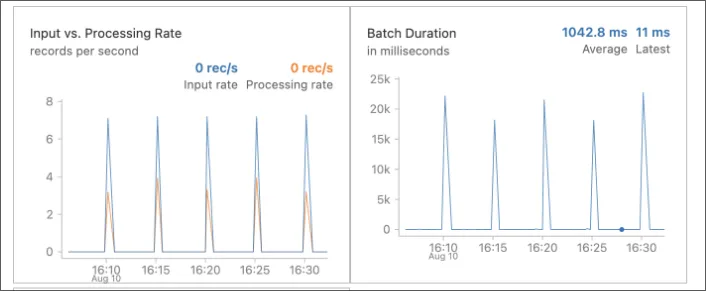
Solution: Implemented streaming architecture with 10-second micro-batch processing achieving 18-second end-to-end latency from collection to queryable storage.
Cloud GPU Cost Barriers
Real-time transformer model inference on cloud GPUs (Azure NC-series, AWS p3 instances) incurs prohibitive costs for sustained monitoring. Premium GPU instances cost $3-5/hour, making 24/7 processing economically infeasible for most organizations at scale.
Solution: Hybrid architecture separating managed cloud services (collection/storage) from academic T4 GPU compute, achieving 95% cost reduction while maintaining equivalent performance to premium cloud instances.
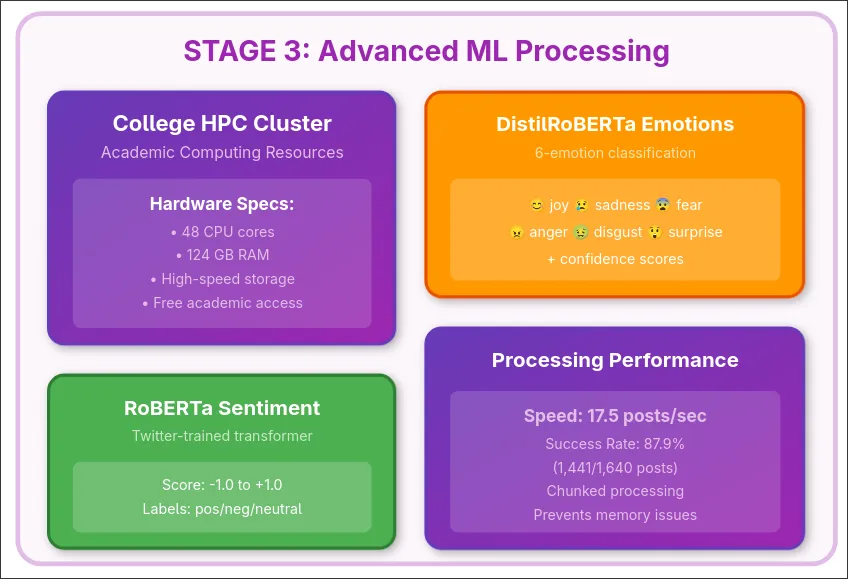
Accuracy-Speed Tradeoff
Lexicon-based methods (VADER) achieve only 60-61% accuracy on social media text due to sarcasm, context-dependent language, and evolving linguistic patterns. Transformer models provide superior accuracy but introduce latency and computational complexity unsuitable for streaming applications.
Solution: Deployed pre-trained RoBERTa and DistilRoBERTa models with chunked batch processing (size 32), achieving 17.5 posts/second throughput on academic hardware.
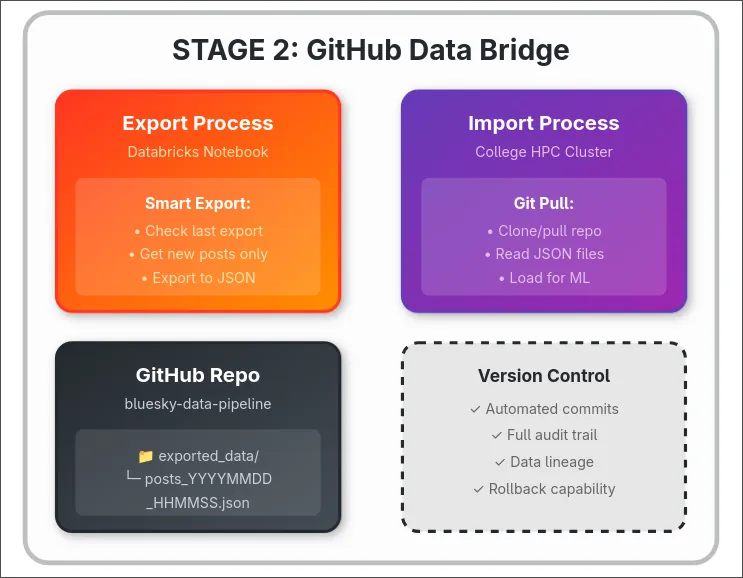
GitHub Data Bridge Innovation
Designed a novel bidirectional data transfer mechanism using GitHub's REST API that enables Databricks (Azure cloud) to exchange data with academic compute resources without direct network connectivity or VPN configuration. The bridge implements:
- Export Logic: Databricks notebooks query Delta Lake for posts with timestamps newer than last successful export, encoding JSON data in Base64 format for transmission via GitHub API content creation endpoint
- Incremental Processing: Timestamp-based watermarks track processing state, typically resulting in 100-500 post batches during regular operation
- Bidirectional Flow: Raw data flows to incremental/ directory, enhanced ML results return through enhanced/ directory with manifest files ensuring data integrity
- Academic Sync: Automated git pull operations every 30 minutes with file-based locking to prevent concurrent processing
- Reliability: Retry logic for API rate limiting (5000 requests/hour) and commit SHA verification for successful uploads
Impact: Platform-independent integration pattern enabling flexible compute allocation while maintaining enterprise-grade reliability. This architecture validates that GitHub can serve as an effective data bridge for hybrid cloud-academic pipelines.